Mobile Text-to-Image Search(MoTIS)
MoTIS is a minimal demo demonstrating semantic multimodal text-to-image search using pretrained vision-language models. Semantic search represents each sample(text and image) as a vector in a shared semantic embedding space. The relevance score can then be measured as similarity(cosine similarity or distance) between vectors.
Distilled Image Encoder Checkpoints
| Model | Google Drive | Hit@10 on MSCOCO 2017 |
|---|---|---|
| original CLIP(336MB) | https://drive.google.com/file/d/1K2wIyTuSWLTKBXzUlyTEsa4xXLNDuI7P/view?usp=sharing | 58.6 |
| Deit-small-distilled-patch16-224(84MB) | https://drive.google.com/file/d/1Fg3ckUUqBs5n4jvNWZUcwwk7db0QBRri/view?usp=sharing | 62.1 |
| ViT-small-patch16-224(85MB) | https://drive.google.com/file/d/1s_oX0-HIELpjjrBXsjlofIbTGZ_Wllo0/view?usp=sharing | 63.8 |
| ViT-small-patch16-224(train with larger batch size) | https://drive.google.com/file/d/1h_w9msJMB4F-dR6uNwp-BHeguS5QIrnE/view?usp=sharing | 64.7 |
Note that these ckpts are not ckpt from state_dict(), but rather the ckpt after torch.jit.script operation. The same original CLIP text encoder is used for all various image encoders.
Recent Updates:
- We use pretrained ViT-Small(85MB) as initialization for the student model. Using the same distillation pipeline, it achieves even better results(2 points higher Hit@1) than the previous Deit-small-distilled model. Link of the jit scirpt checkpoint is here.
- A more effective distilled image encoder(84MB compared to the original 350MB ViT-B/32 in CLIP) is available here. This image encoder is initialized with DeiT-base-distilled's pre-trained weights, which leads to more robust image representation hence better retrieval performance(obtain higher Hit@1/5/10 than original CLIP on MSCOCO validation set). It is further learned through supervised learning and knowledge distillation.
- Transplanted Spotify's Annoy Approximate Nearest Neighbor search in this project(annoylib.h).
- Relatively low quality images are displayed by default. Retrieved images are displayed with high quality. This is designed to reduce the runtime memory.
Features
- text-to-image retrieval using semantic similarity search.
- support different vector indexing strategies(linear scan, KMeans, and random projection).
Screenshot
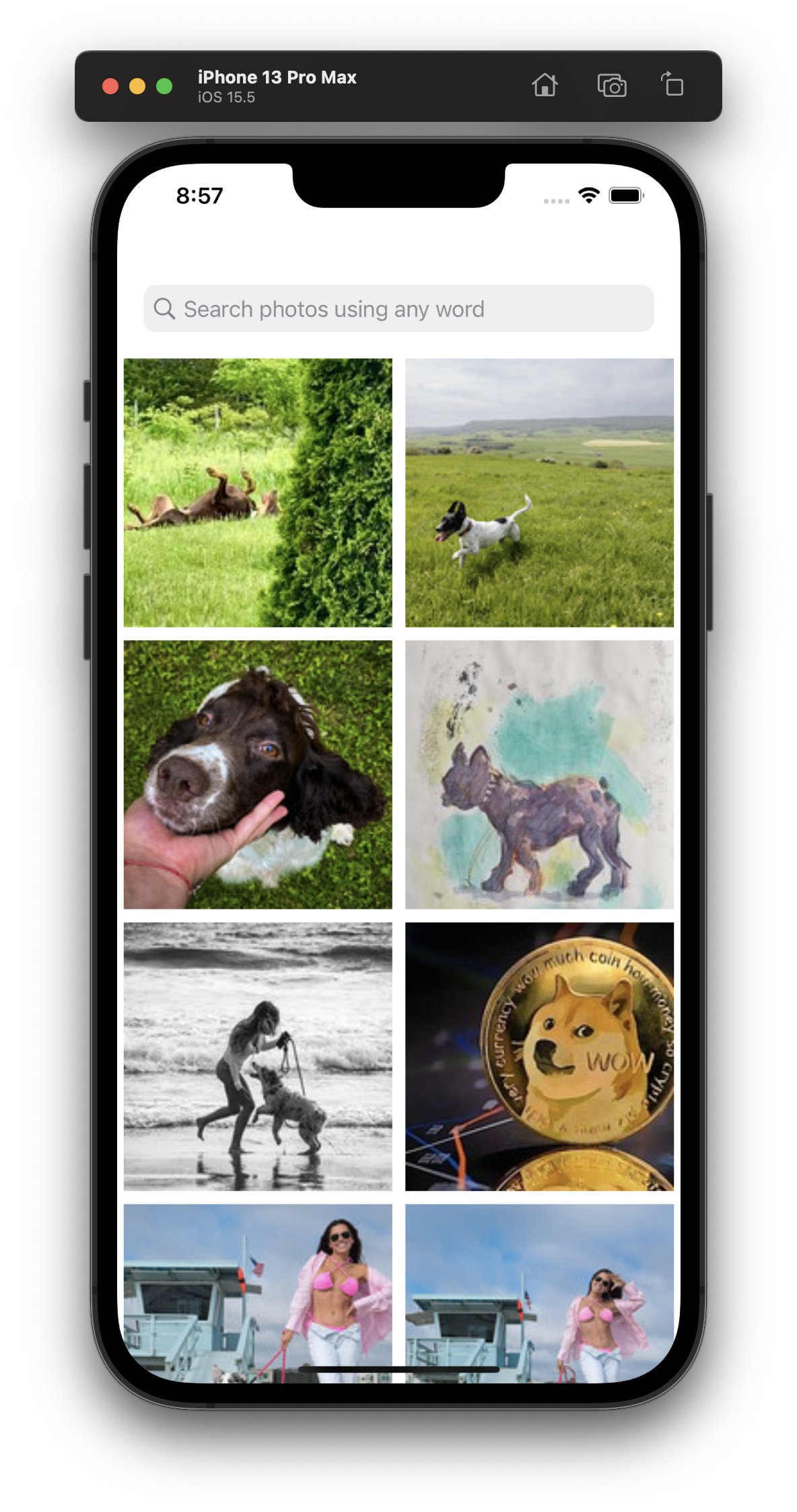
- All images in the gallery

- Search with query Three cats

Installation
- Download the two TorchScript model files(text encoder, image encoder) into models folder and add them into the Xcode project.
- Required dependencies are defined in the Podfile. We use Cocapods to manage these dependencies. Simply do 'pod install' and then open the generated .xcworkspace project file in XCode.
pod install
- This demo by default load all images in the local photo gallery on your realphone or simulator. One can change it to a specified album by setting the albumName variable in getPhotos method and replacing assetResults in line 117 of GalleryInteractor.swift with photoAssets.
Usage
Just type any keyword in order to search the relecant images. Type "reset" to return to the default one.
Todos
- Basic features
- Access to specified album or all photos
- Asynchronous model loading and vectors computation
- Export pretrinaed CLIP into TorchScript format using torch.jit.script and optimize_for_mobile provided by Pytorch
- Transplant the original PIL based image preprocessing procedure into OpenCV based procedure, observed about 1% retrieval performance degradation
- Transplant the CLIP tokenizer from Python into Swift(Tokenizer.swift)
- Indexing strategies
- Linear indexing(persisted to file via built-in Data type)
- KMeans indexing(persisted to file via NSMutableDictionary, hard-coded num of clusters, u can change to whatever u want)
- Spotify's Annoy libraby with random projection indexing, the size of index file is 41MB for 2200 images.
- Choices of semantic representation models
- OpenAI's CLIP model
- Integration of other multimodal retrieval models
- Effiency
- Reducing memory consumption of models: runtime memory 1GB -> 490MB via a smaller yet effective distilled ViT model.
About Us
This project is actively maintained by ADAPT lab from Shanghai Jiao Tong University. We expect it to continually integrate more advanced features and better cross-modal search experience. If you have any problems, welcome to file an issue.
 0 Jan 6, 2022
0 Jan 6, 2022

 2.8k Jan 3, 2023
2.8k Jan 3, 2023

 11 Jan 10, 2022
11 Jan 10, 2022
 0 Feb 26, 2022
0 Feb 26, 2022

 8 Dec 16, 2022
8 Dec 16, 2022

 6 Sep 20, 2022
6 Sep 20, 2022
 1 Jun 6, 2022
1 Jun 6, 2022

 44 Dec 18, 2022
44 Dec 18, 2022


 1 Nov 11, 2021
1 Nov 11, 2021
 478 Dec 17, 2022
478 Dec 17, 2022
 2 Oct 28, 2022
2 Oct 28, 2022
 1.6k Jan 6, 2023
1.6k Jan 6, 2023
 1.8k Dec 30, 2022
1.8k Dec 30, 2022
 222 Dec 17, 2022
222 Dec 17, 2022
 5.6k Jan 5, 2023
5.6k Jan 5, 2023
 330 Sep 9, 2022
330 Sep 9, 2022
 1k Jan 4, 2023
1k Jan 4, 2023
 1.8k Dec 17, 2022
1.8k Dec 17, 2022